



AI活用のプロンプトエンジニアリングに関する特許取得について

株式会社クラウドシフトは大規模言語モデル(以下LLM)を利用したシステム開発について、
要件定義や基本設計情報を効率良くLLMに渡し解釈させるためのプロンプトエンジニアリング技術について2024年10月21日に特許を取得しました。
本特許によって業務システム開発でLLMを有効活用し、設計から製造、テストデバッグに至る開発工数を劇的に削減することを目指します。
またLLMによる大規模システム開発への道を拓きます。
■特許の概要:
業務システム等のユースケースをはじめとする要件定義情報と、基本設計情報(画面、画面要素、機能、DB、バッチ、外部APIなど)
を全てリスト管理、階層管理することにより特定のドキュメントノード単位やドキュメントツリー単位でMarkdownやJSONなど
大規模言語モデル(以下LLM)が解釈しやすい形式に自動的に加工してプロンプトを発行し、
そこで得られるソースコードのバージョン管理情報も階層に紐付けすることによって、統合的なシステム開発を行います。
テストケースも階層的に紐付けて修正デバッグも効率化して大規模なシステム開発を行うことを目的とした基本特許となります。
特許番号:第7575148号
発明の名称:情報処理方法、プログラムおよび情報処理システム
1.統合的なソース管理
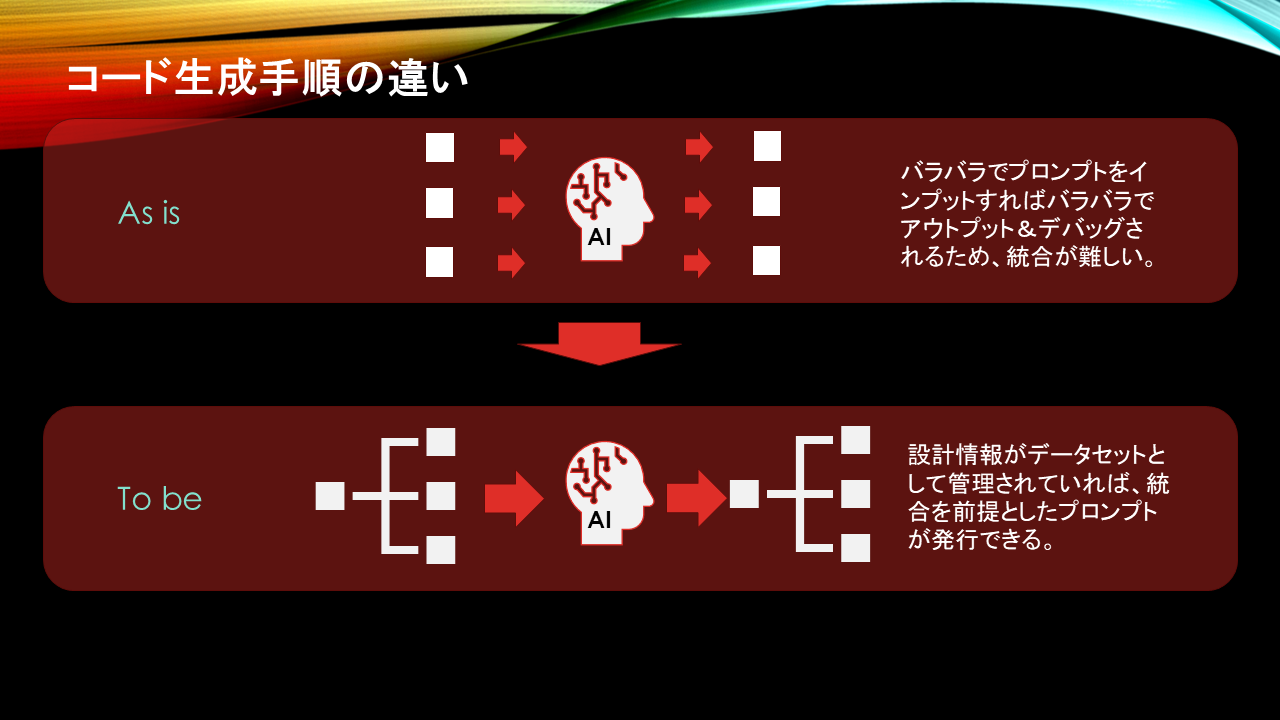
As is:プログラマとLLMとの1対1のコーディング・・・部分的なコーディングとデバッグの繰り返しが必要なため、劇的な工数削減ができない。
To be:システム設計者とLLMとの1対Nのコーディング・・・ソースコード生成段階である程度統合を意識した状態で出力されるため、システム全体として統合的なコード生成と統合的なデバッグ環境が構築できる。
従来LLMによるプロンプトエンジニアリングはプログラマとLLMとの1対1の対話の繰り返しによりシステムを作り上げてきました。
よってシステム全体ではなく、システムの一部分をコーディング&デバッグのプロセスを繰り返して最終的に組み上げてゆくのは人手で行う必要があり非効率的でした。
たしかにLLMのマルチモーダル化によってワイヤフレームから画面のソースコードを一体生成することはできます。
しかし作成した画面上のボタンやフォーム等と連携する機能については別途作成して人がClassやidやスクリプトを指定して画面と結合する必要があり、開発の単位が細かすぎて一貫性効率性が確保できませんでした。
データベースとの連携も然りです。
要件定義、基本設計段階から全ての情報を階層管理することによって、例えば次のような連鎖で一貫性を持たせたシステム開発を行うことが可能になります。
よってシステム全体ではなく、システムの一部分をコーディング&デバッグのプロセスを繰り返して最終的に組み上げてゆくのは人手で行う必要があり非効率的でした。
たしかにLLMのマルチモーダル化によってワイヤフレームから画面のソースコードを一体生成することはできます。
しかし作成した画面上のボタンやフォーム等と連携する機能については別途作成して人がClassやidやスクリプトを指定して画面と結合する必要があり、開発の単位が細かすぎて一貫性効率性が確保できませんでした。
データベースとの連携も然りです。
要件定義、基本設計段階から全ての情報を階層管理することによって、例えば次のような連鎖で一貫性を持たせたシステム開発を行うことが可能になります。
アクター⇒ユースケース⇒必要な画面一覧⇒必要な画面要素一覧⇒関連する機能一覧⇒必要なデータオブジェクト⇒正規化されたデータベース
これは飽くまでも一例であり、同様の流れで階層構造を持たせて管理することで様々なシステムの構築に必要なソースコード管理が統合的にできると考えています。2.LLMによる設計支援
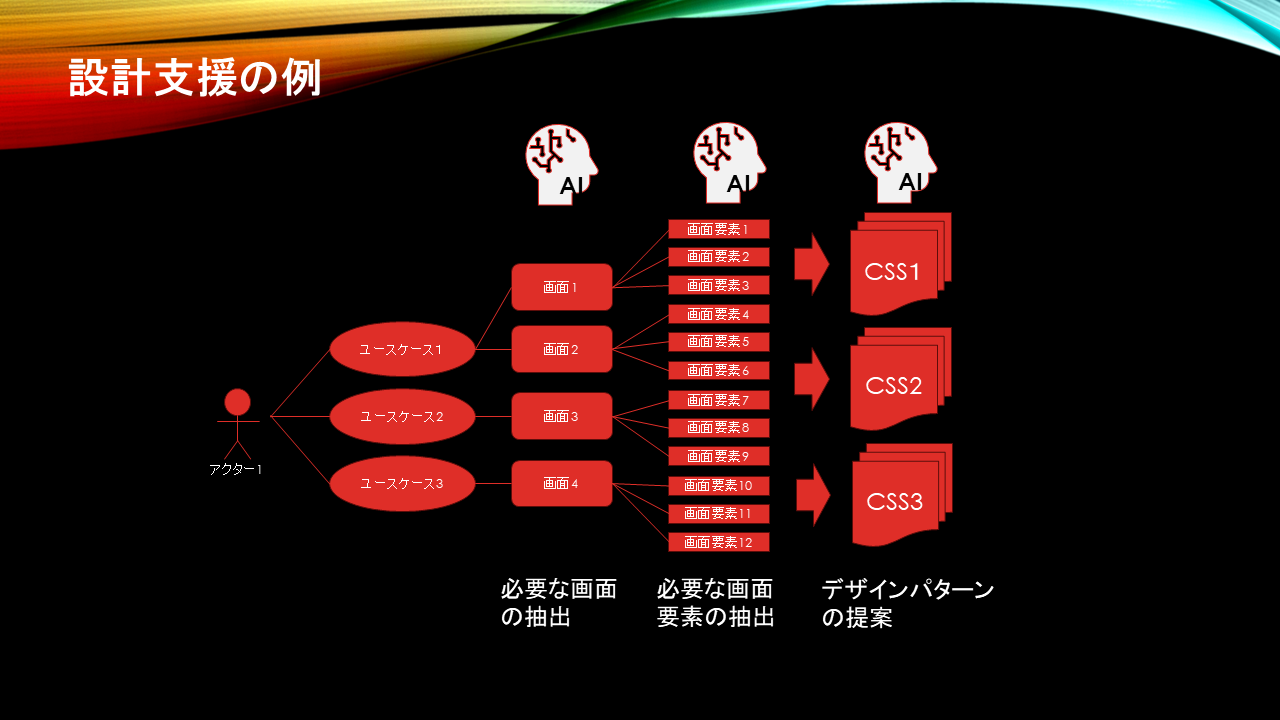
AIに段階的に提案をさせた結果をデータセットとして管理してこれを繰り返し、階層管理することによって、統合的なプロンプトの発行が可能になります。
AIからの結果をJSONで返せば、そのままリストや階層構造として保存が可能です。
左図の例ではユースケースから画面と画面要素をLLMに提案させて、その組み合わせを元にCSSを提案させています。
従来システム設計者は全ての項目を漏れの無いように練り上げる必要がありました。
設計者の経験やスキルに依存するため、設計段階でとん挫する例もありました。
今回の特許を利用して、ヒアリングリストを埋めてゆくだけで、あとは対話的に設計を進めてゆくことを目論んでいます。
基本的な要件定義についてはヒアリング力が問われるのは従来とかわりませんが、ある程度情報が揃えばあとはLLMとの対話で設計支援を得ることが可能になります。
例えばショッピングサイトを作りたいのであればLLMに問い合わせれば容易にアクターやユースケースを抽出してくれます。
購入者が使う画面であればログイン画面、商品検索画面、商品情報詳細画面などLLMとの壁打ちで直ぐに提案してもらえます。
その中で商品情報詳細画面であれば商品名、商品の写真、諸元、価格、ショッピングカート、関連商品のレコメンデーションなど概ね必要な画面要素は提案してもらえます。 画面要素が決まればLLMにCSSを提案させて画面デザインを起こすこともできますし、画面に関連付けた機能開発が可能になり、必要なデータオブジェクトも決まってきます。
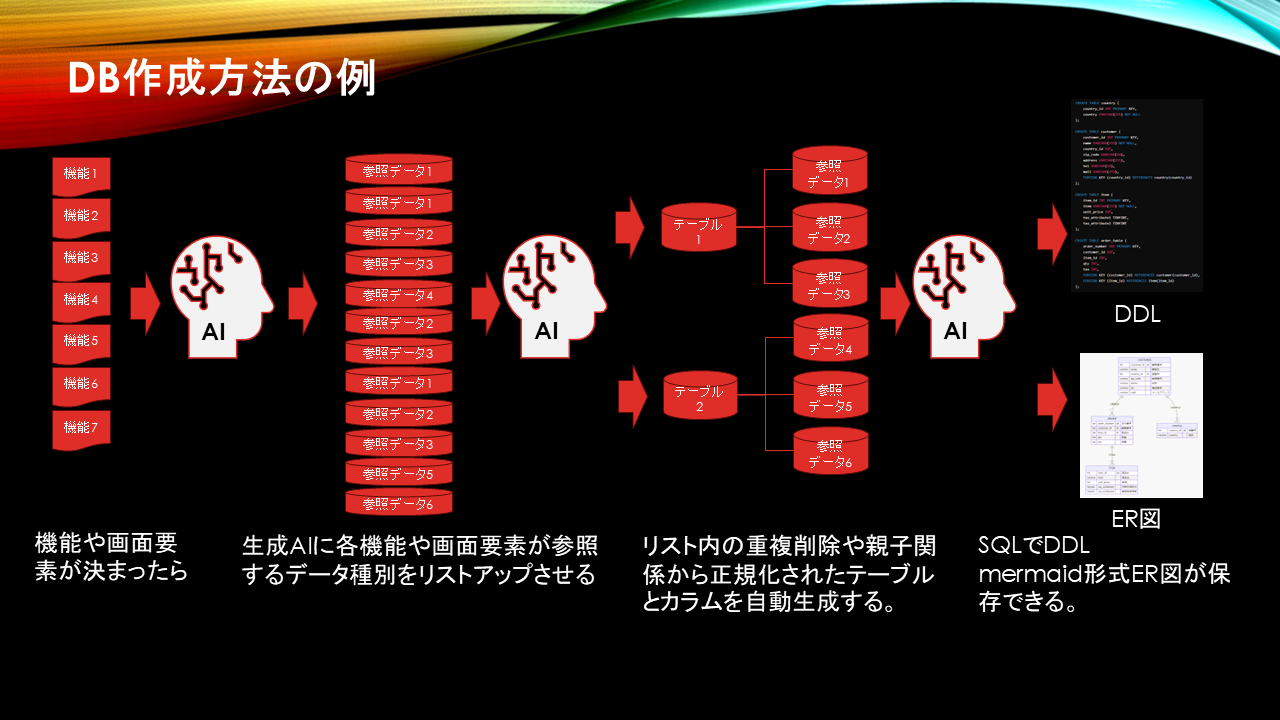
データオブジェクトが出そろえば重複削除してLLMに正規化を依頼してデータベースを構築することもできます。
これらの連鎖を全てリスト化、階層化し、それをもとにLLMに対して一定のルールでプロンプトを自動発行することによって、生成されるソースコードに一貫性を持たせる仕組みができあがります。
こうしてデータ管理された設計情報からノード単位、階層ツリー単位でプロンプトをMarkdownやJSONで発行して細かい部分を補完することによって自然言語より明確な指示をLLMに与えることが可能になります。
このリスト化、階層化による副産物として、設計ドキュメントも自動生成できます。
PlantUML形式やMermaid形式でユースケース図、業務フローを可視化するスウィムレーン図、システムの流れを表わすシーケンス図、個々のプログラムの振る舞いを示すフローチャート、データベースを定義するER図など、 人は設計図面で、LLMにはテキストベースでインプットすることができるため、人もLLMも直感的に解釈できる情報としてシステムの全体像を伝えることができるのです。
AIからの結果をJSONで返せば、そのままリストや階層構造として保存が可能です。
左図の例ではユースケースから画面と画面要素をLLMに提案させて、その組み合わせを元にCSSを提案させています。
従来システム設計者は全ての項目を漏れの無いように練り上げる必要がありました。
設計者の経験やスキルに依存するため、設計段階でとん挫する例もありました。
今回の特許を利用して、ヒアリングリストを埋めてゆくだけで、あとは対話的に設計を進めてゆくことを目論んでいます。
基本的な要件定義についてはヒアリング力が問われるのは従来とかわりませんが、ある程度情報が揃えばあとはLLMとの対話で設計支援を得ることが可能になります。
例えばショッピングサイトを作りたいのであればLLMに問い合わせれば容易にアクターやユースケースを抽出してくれます。
購入者が使う画面であればログイン画面、商品検索画面、商品情報詳細画面などLLMとの壁打ちで直ぐに提案してもらえます。
その中で商品情報詳細画面であれば商品名、商品の写真、諸元、価格、ショッピングカート、関連商品のレコメンデーションなど概ね必要な画面要素は提案してもらえます。 画面要素が決まればLLMにCSSを提案させて画面デザインを起こすこともできますし、画面に関連付けた機能開発が可能になり、必要なデータオブジェクトも決まってきます。
データオブジェクトが出そろえば重複削除してLLMに正規化を依頼してデータベースを構築することもできます。
これらの連鎖を全てリスト化、階層化し、それをもとにLLMに対して一定のルールでプロンプトを自動発行することによって、生成されるソースコードに一貫性を持たせる仕組みができあがります。
こうしてデータ管理された設計情報からノード単位、階層ツリー単位でプロンプトをMarkdownやJSONで発行して細かい部分を補完することによって自然言語より明確な指示をLLMに与えることが可能になります。
このリスト化、階層化による副産物として、設計ドキュメントも自動生成できます。
PlantUML形式やMermaid形式でユースケース図、業務フローを可視化するスウィムレーン図、システムの流れを表わすシーケンス図、個々のプログラムの振る舞いを示すフローチャート、データベースを定義するER図など、 人は設計図面で、LLMにはテキストベースでインプットすることができるため、人もLLMも直感的に解釈できる情報としてシステムの全体像を伝えることができるのです。
3.プロンプトエンジニアリングの改革
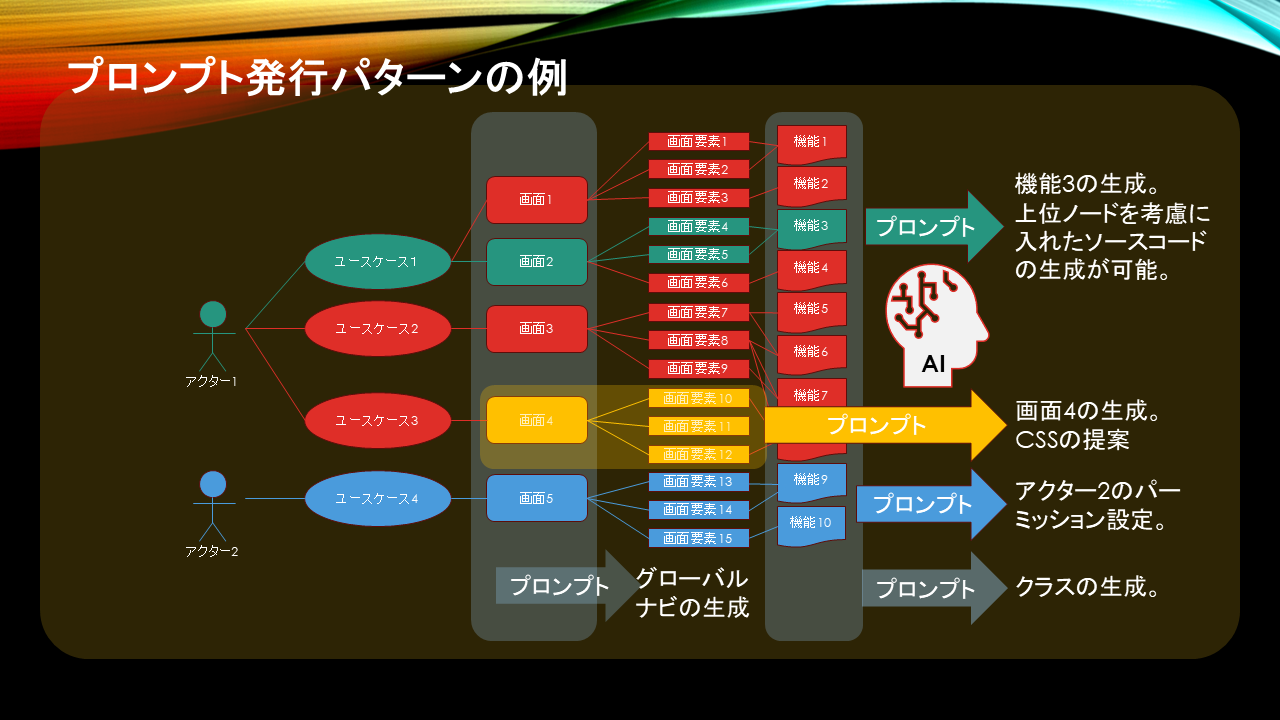
設計ドキュメントのデータセットを元に、ノード単位、ドキュメントツリー単位で多角的に様々なプロンプトを発行し、設計情報を正確にLLMに伝える仕組みを提供します。
例えば機能からドキュメントツリーを遡ってプロンプトを発行すれば設計の前後関係を的確にソースコードに反映できます。画面の一覧からはグローバルメニューが生成できますし、
アクターから順にドキュメントツリーを辿れば画面や画面要素に対するアクセス権の設定ができます。
画面と画面要素の抽出が完了していれば、そこから画面レイアウトの提案をLLMに要求してCSSのパターンを提案させることも可能になります。
更に数多くある機能を分類することでLLMにクラス図を作らせることもできるでしょう。 設計の過程で得られるスウィムレーン図、シーケンス図、ER図などをLLMにテキストベースで投入すれば全体的な動作やフローを把握させることも可能です。
画面と画面要素の抽出が完了していれば、そこから画面レイアウトの提案をLLMに要求してCSSのパターンを提案させることも可能になります。
更に数多くある機能を分類することでLLMにクラス図を作らせることもできるでしょう。 設計の過程で得られるスウィムレーン図、シーケンス図、ER図などをLLMにテキストベースで投入すれば全体的な動作やフローを把握させることも可能です。
4.テスト自動化
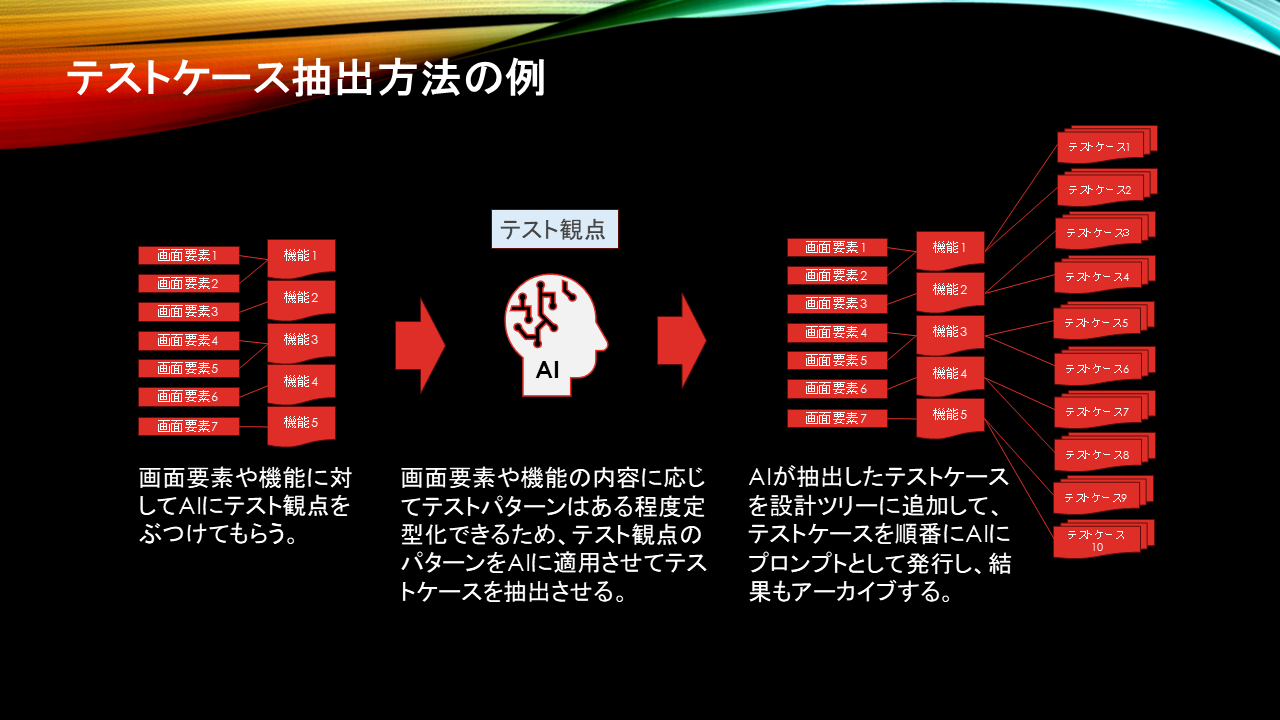
設計情報が全て階層管理されるということは、それに紐付いてテストケースも関連付けられるということになります。
階層化された設計情報から画面要素や機能を順番に生成AIに対して照合をかけて考えられるテスト観点をぶつけてテストケースを抽出し、テストケースを設計情報の階層に追加します。
また追加されたテストケースを順次実行するプロンプトを発行してテスト自動化を行います。
5.システム化のイメージ
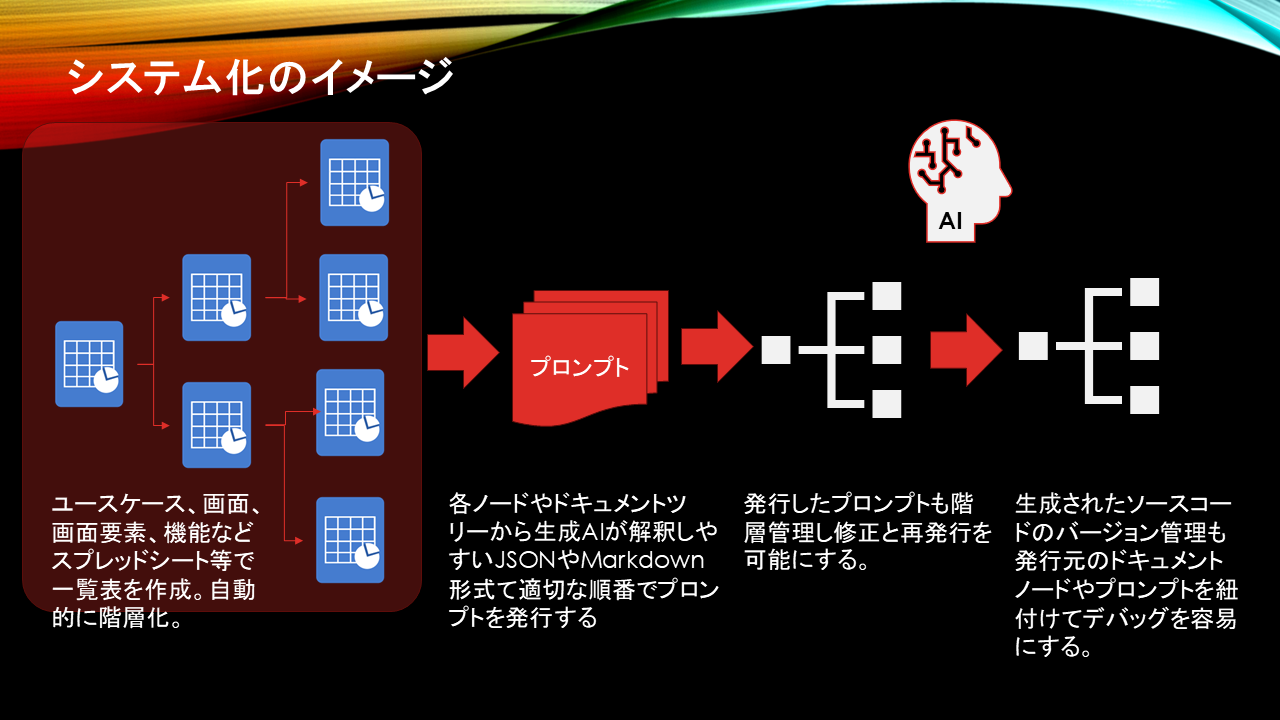
最終的なゴールは、システム設計者一人で大規模な業務システムを作り上げることです。
システムエンジニアやITコンサルタントは勿論、情報システム部の担当者が社内の製造部門や経理部門にヒアリングしながらシステム開発ができるプラットフォームを構築したいと考えております。
そのためにはシンプルで対話型のUIが必須でコードは生成するもののオペレーション自体はノーコードやローコードにして直感的に操作できる必要があると考えております。 基本情報だけスプレッドシートに登録すれば、次のアクションはAIとの対話で叩き台になるデータが自動登録され、それを編集しながら先に進んでゆくようなものを検討しております。
そのためにはシンプルで対話型のUIが必須でコードは生成するもののオペレーション自体はノーコードやローコードにして直感的に操作できる必要があると考えております。 基本情報だけスプレッドシートに登録すれば、次のアクションはAIとの対話で叩き台になるデータが自動登録され、それを編集しながら先に進んでゆくようなものを検討しております。